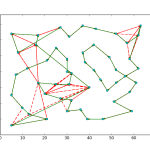
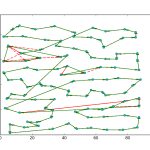
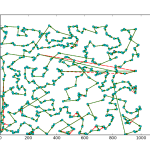
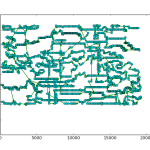
So a few days ago I showed off some results of using a line profiler package to get detailed feedback on python programs. Using the package, I found out that my cost calculation algorithm for a Tabu Search implementation for the Traveling Salesman Problem (TSP) was the major bottleneck in my code. After playing around with the function and reading some forums, I figured out a way to significantly improve the cost function. I was originally computing the cost of the entire TSP path for every 2-Opt iteration. It turns out that this was a fairly excessive calculation, as I was only swapping the positions of two nodes at a time, the resulting change to the total cost was simply the distances between the two nodes and their respective neighbors. So I modified the function to accept the position of the two nodes, and then calculated the distance of those partial routes to identify swaps that increased the solution’s optimality.
The original code is posted below. In this function, I pass in a list of index values that correspond to the order in which the nodes are visited and then the function computes the total distance of the path, including the return trip to the starting point.
def calc_cost(perm): distance = length(points[perm[-1]], points[perm[0]]) for i in range(0, nodeCount-1): distance += length(points[perm[i]], points[perm[i+1]]) return distance
In the modified function, shown below, I pass in the same list as before, however I added another argument to the function that indicates the position of the path that I want to evaluate. The function then calculates the distance between the provided position and the node directly before and after it in the path. I call this function four times when evaluating a 2-Opt iteration, twice to evaluate the change in the two points that were swapped, and twice again to evaluate the original distance in the path. If the total segmented distance of the two swapped points is lower than the total segmented distance of the original two points, I keep the modified solution as it will have a lower total distance.
def calc_seg_cost(perm, c):
if c != len(perm) - 1:
seg = [perm[c-1], perm, perm]
else:
seg = [perm[c-1], perm, perm[0]]
distance = 0
for i in range(0, len(seg)-1):
distance += length(points[seg[i]], points[seg[i+1]])
return distance
I ran the two different versions of the code on a number of TSP problems and recorded the time of each run using the unix time utility. I then plotted the results using matplotlib.
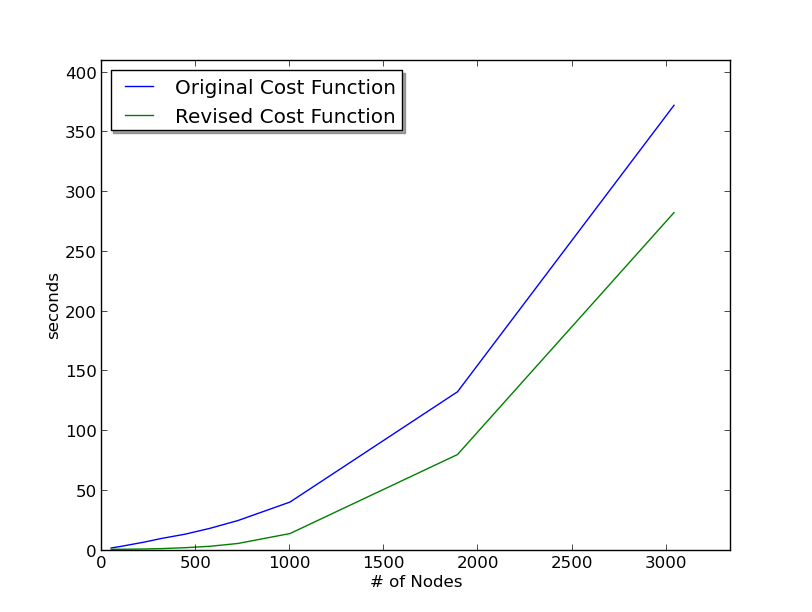
As you can see from the plot, the function modification appears to be saving a substantial amount of time. The primary advantage of this modification is that I can run my algorithm for a higher number of iterations and get better optimatily in the 5 hour time frame that we have. This should help me improve my scores, but I may still need to keep tweaking the algorithm if I want to get higher scores on the larger problems, as it looks like the cost function modification by itself will not be enough to achieve that goal.