Today, sadly, I will be pulling down the CL-App site. The site has been somewhat non-operational for a while now, as the IP address has been blocked by Craigslist. I never meant for the site to be anything more than a demo project, so it was surprising that Craigslist was able to detect the activity. Anyways, for posterity’s sake, I am going to do a quick overview of the site with some screenshots.
Disclaimer: Before Launching into the overview, i think it is worth discussing my thoughts on web scraping. While I think scraping is a very handy tool to have, I also think it needs to be used responsibly. If there is an API available, that should always be used instead. I built the app for my own entertainment and education, it was a great way to learn how to stitch together a number of python libraries and frameworks into a fully functional site. I had a long list of features and improvements that I though would be cool to implement, but in the end, because I knew Craigslist is hostile to scrapers, I felt it would be best too leave it as is and move on to other projects.
A Brief Overview
The purpose of the site was to alert users when new posts were created under a certain search criteria. The alerts could be sent via e-mail or text message. In order to prevent too many requests to Craigslist, the app would check for new updates once per hour, but the user could specify longer intervals between alerts if desired. Below are some slides showing screenshots of the site.
-
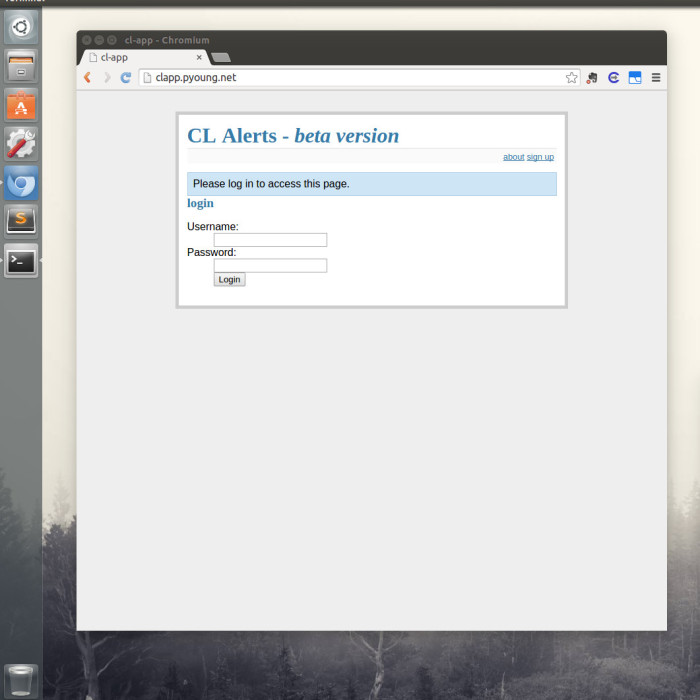 Login Page
Login Page
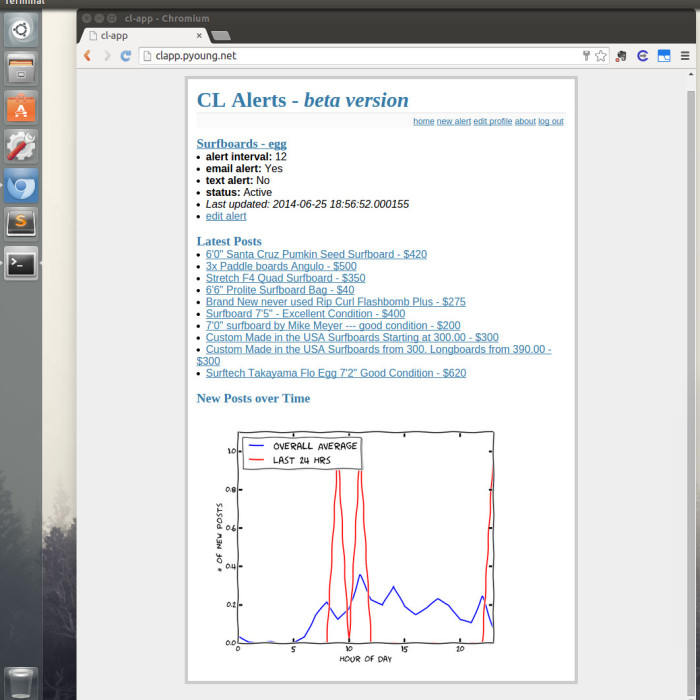
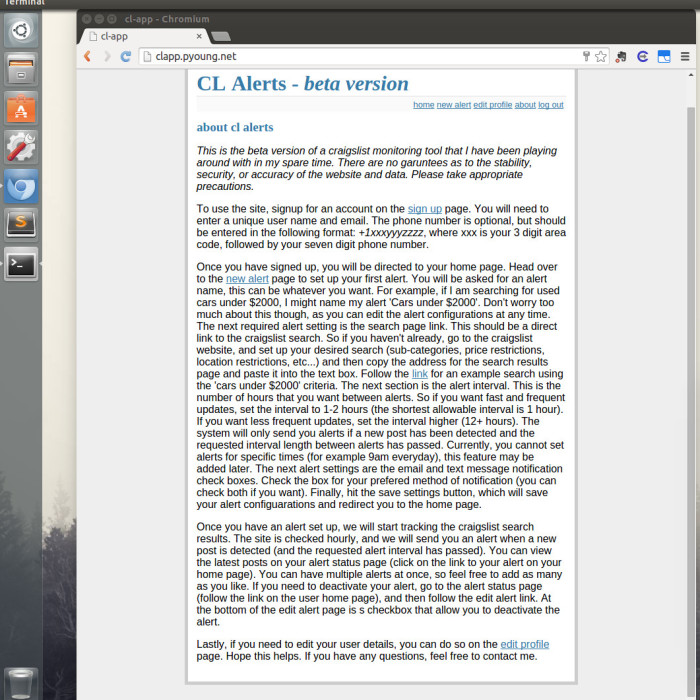
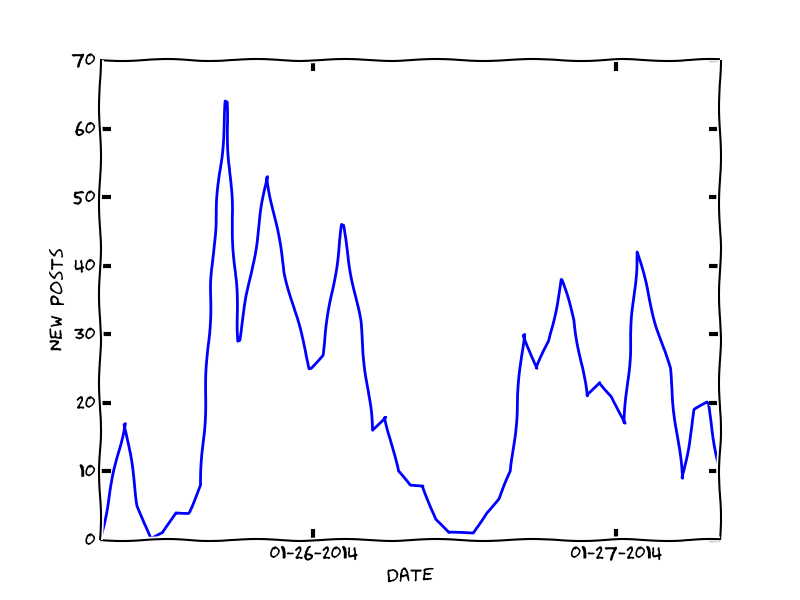
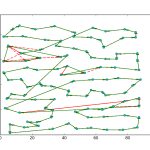
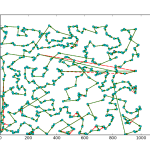
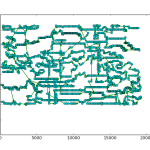
As you can see, the site was pretty bare bones. Considering the main purpose of the app was to send alerts I didn’t feel the need to invest much time in the frontend. I did add a feature that returned a xkcd style matplotlib plot that compared the number of new posts in the last 24 hours to the average number of new posts by hour. Had I put more time into this project, adding some more analytics would have been fun.
If I had to rate the usefulness of this application on a scale of 1 (useless) to 10 (useful), I would give it about a 4 or 5. I tested it out with a handful of different searches, and never found the alerts to be that useful. Because I limited the alert interval to a minimum of an hour, this service wasn’t very useful for items that moved very quickly (i.e. free items). In those cases, you would probably want a minimum of 15 minutes between scrapes. I do think it would work well for someone looking for a very specific or rare item, but I never really bothered to test that hypothesis. One feature that I found useful was that the alert status page would display the last 10 posts that fell under your search criteria. I found that switching between my different alert status pages was a very convenient way to quickly check if there was anything interesting under any of the searches. In essence, it was a page of bookmarks for various searches, and I found that to be pretty useful.
It should be noted that Craigslist allows you to save searches and to send e-mail alerts. I just noticed this the other day. You need to have an account with Craigslist and from what I can tell, you cannot control the e-mail alert too much. I just started an alert on their site, so I can report back on that.
Anyways, that is all for now. It was a fun project and a good learning experience, but I am glad to be putting this one away. While I still have a few projects that involve web scraping, and I will continue to dabble with it from time to time, Craigslist is notoriously hostile to scrapers, so getting a cease and desist from them is one less thing I have to worry about.